Opportunities and Challenges
We posit that progress toward general intelligence will require different complementary classes of foundation models, each anchored to a distinct data modality and set of inductive biases. Large language models (LLMs) provide a universal interface for natural and programming languages and have rapidly advanced instruction following, tool use, and explicit reasoning over token sequences. In real-world scenarios involving structured data, LLMs still rely primarily on statistical correlations between word sequences, which limits their ability to accurately capture numerical relationships and causal rules. In contrast, large structured-data models (LDMs) are trained on heterogeneous tabular and relational data to capture conditional and joint dependencies, support diverse tasks and applications, enable robust prediction under distribution shifts, handle missingness, and facilitate counterfactual analysis and feature attribution. Here, we introduce LimiX, the first installment of our LDM series. LimiX aims to push generality further: a single model that handles classification, regression, missing-value imputation, feature selection, sample selection, and causal inference under one training and inference recipe, advancing the shift from bespoke pipelines to unified, foundation-style tabular learning.
LimiX: A Generalist Tabular Model
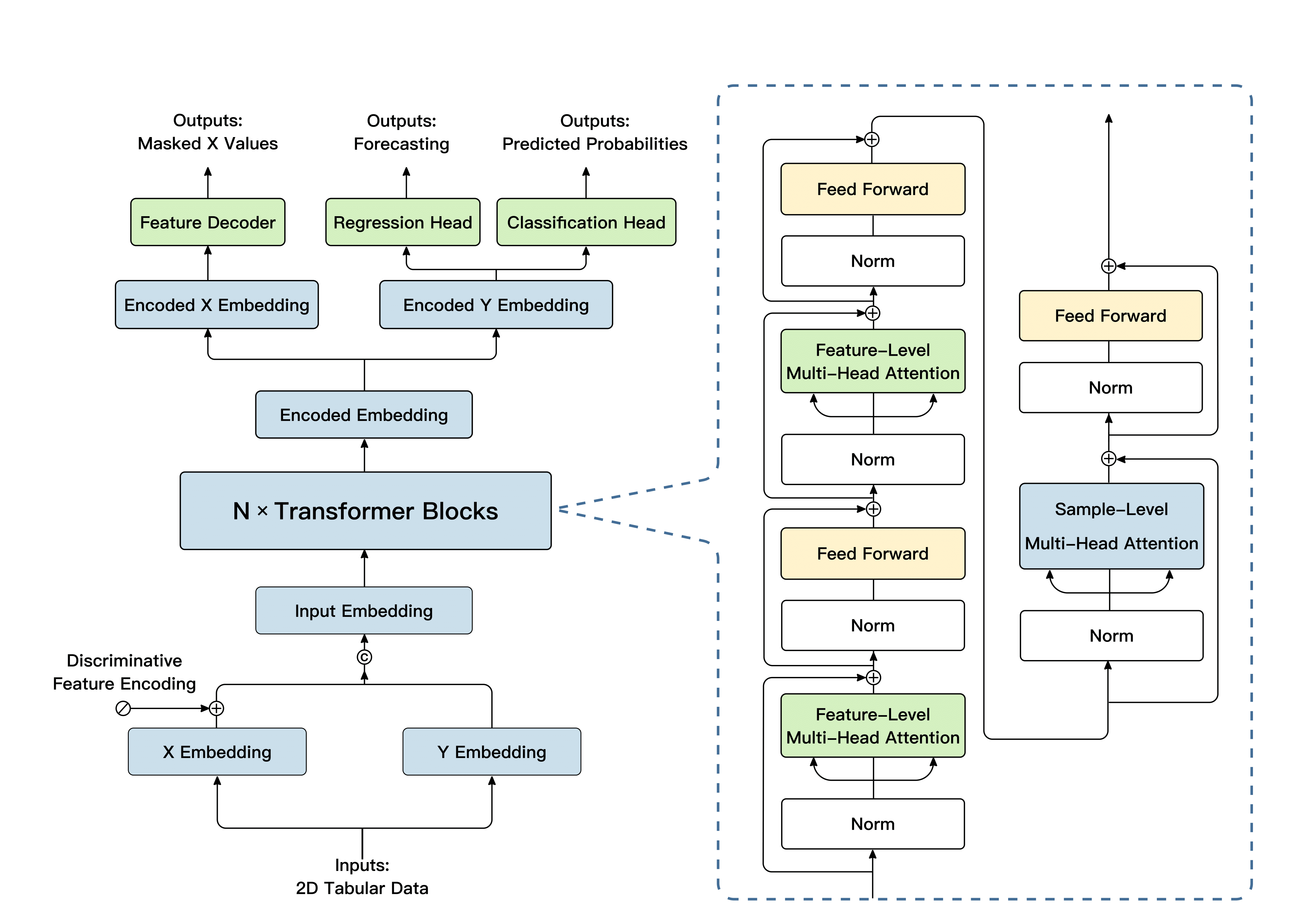
LimiX adopts a transformer architecture optimized for structured data modeling and task generalization. The model first embeds features and targets from the prior knowledge base into token representations. Within the core modules, attention mechanisms are applied across both sample and feature dimensions to identify salient patterns in key samples and features. The resulting high-dimensional representations are then passed to regression and classification heads, enabling the model to support diverse predictive tasks.
Pretraining
LimiX is pretrained by randomly masking cells in each training row and training the model to recover the hidden entries from the observed context. Exposing the model to many mask patterns forces it to master a wide spectrum of conditional relationships among variables; when these conditionals are learned consistently, they effectively define a single joint model of the data. This joint model can then be queried for diverse tasks with one mechanism: treat a chosen column as the target to perform regression or classification, fill in missing values by predicting the masked cells from the observed ones, and generate new samples by iteratively masking and refilling subsets of features.
Data Generation
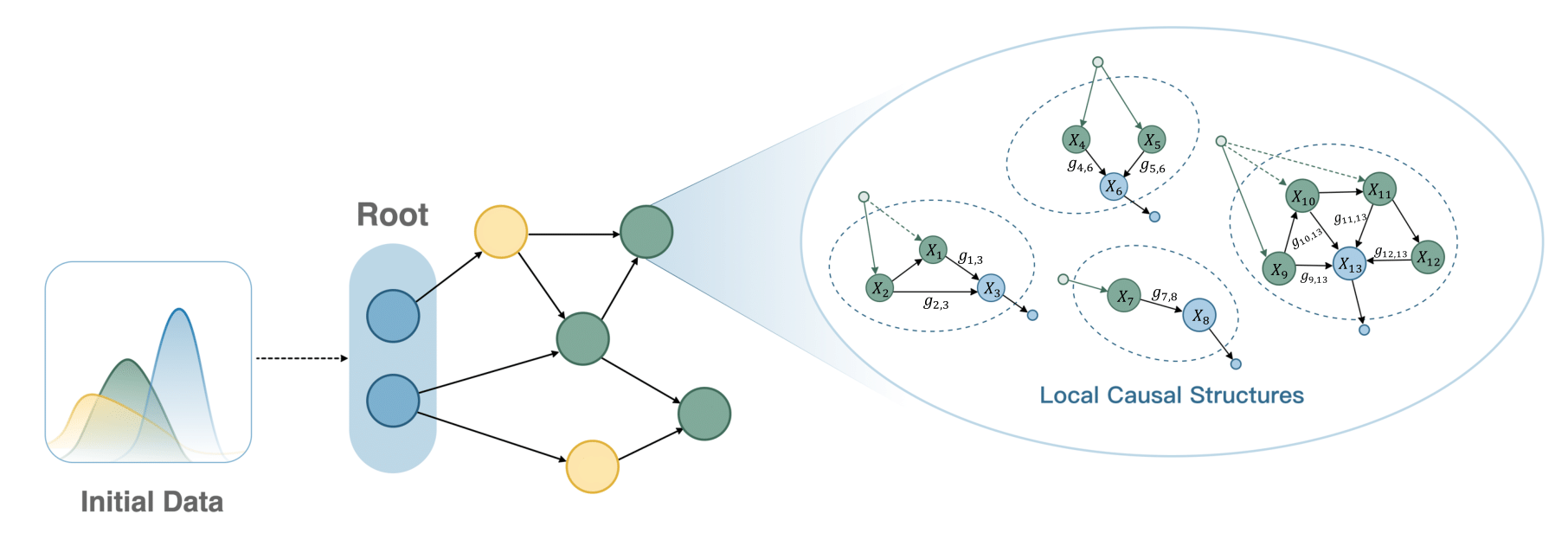
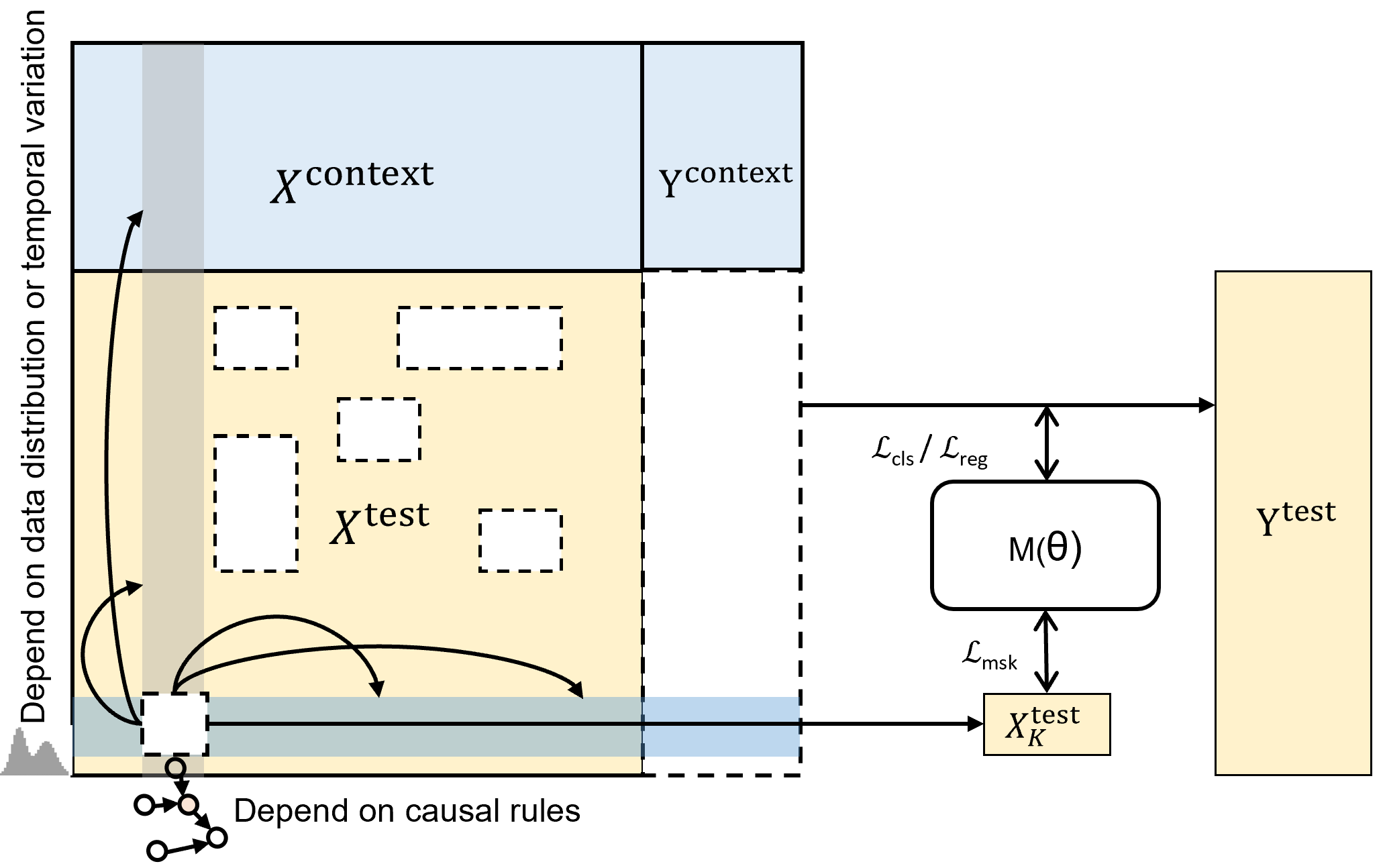
The performance of foundation models largely depend on the diversity and quality of the pretraining data—a critical factor in the training process. Although many open-source tabular datasets are available, they are often poorly maintained, and improving their quality can be either labor-consuming or impractical. To address this, we generate synthetic datasets using Directed Acyclic Graphs (DAGs), whose theoretical foundation lies in structural causal models. The data generation process proceeds in three stages: DAG construction, dataset sampling and task adaptation. In the first stage, we generate diverse local causal structures (LCSs), each encoding distinct causal dependencies. These LCSs are then interconnected following a prescribed procedure to form a complete DAG. In the second stage, data sampled from the DAG are partitioned into input features and targets, using either graph-aware or solvability-aware strategies. The former samples according to the graphical distribution, while the latter emphasizes distinguishing datasets by their degree of solvability. Finally, the sampled data is processed to align with various downstream pretraining tasks. By leveraging the generated data, we ensure both the diversity and quality of the pretraining datasets used by LimiX.
Evaluation
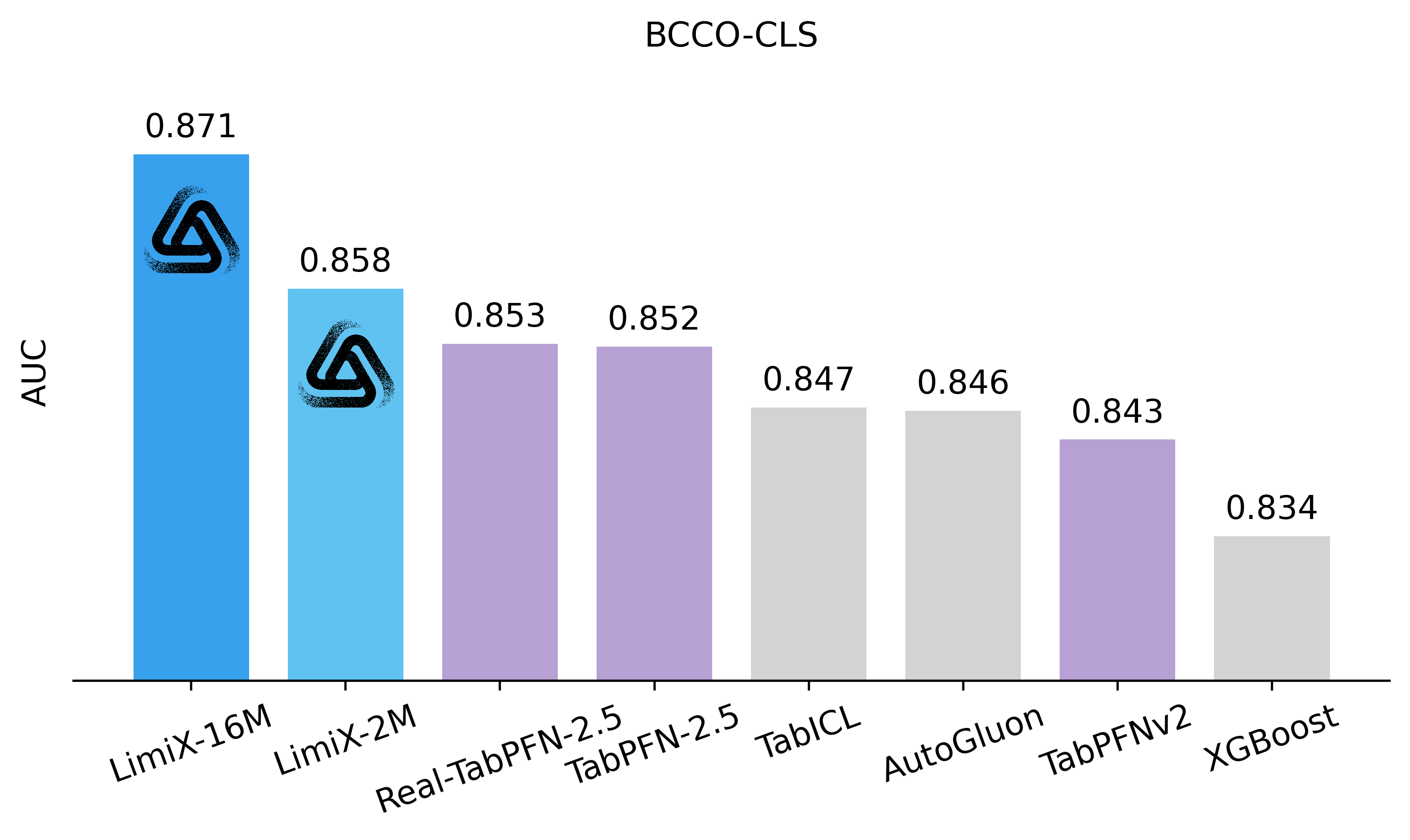
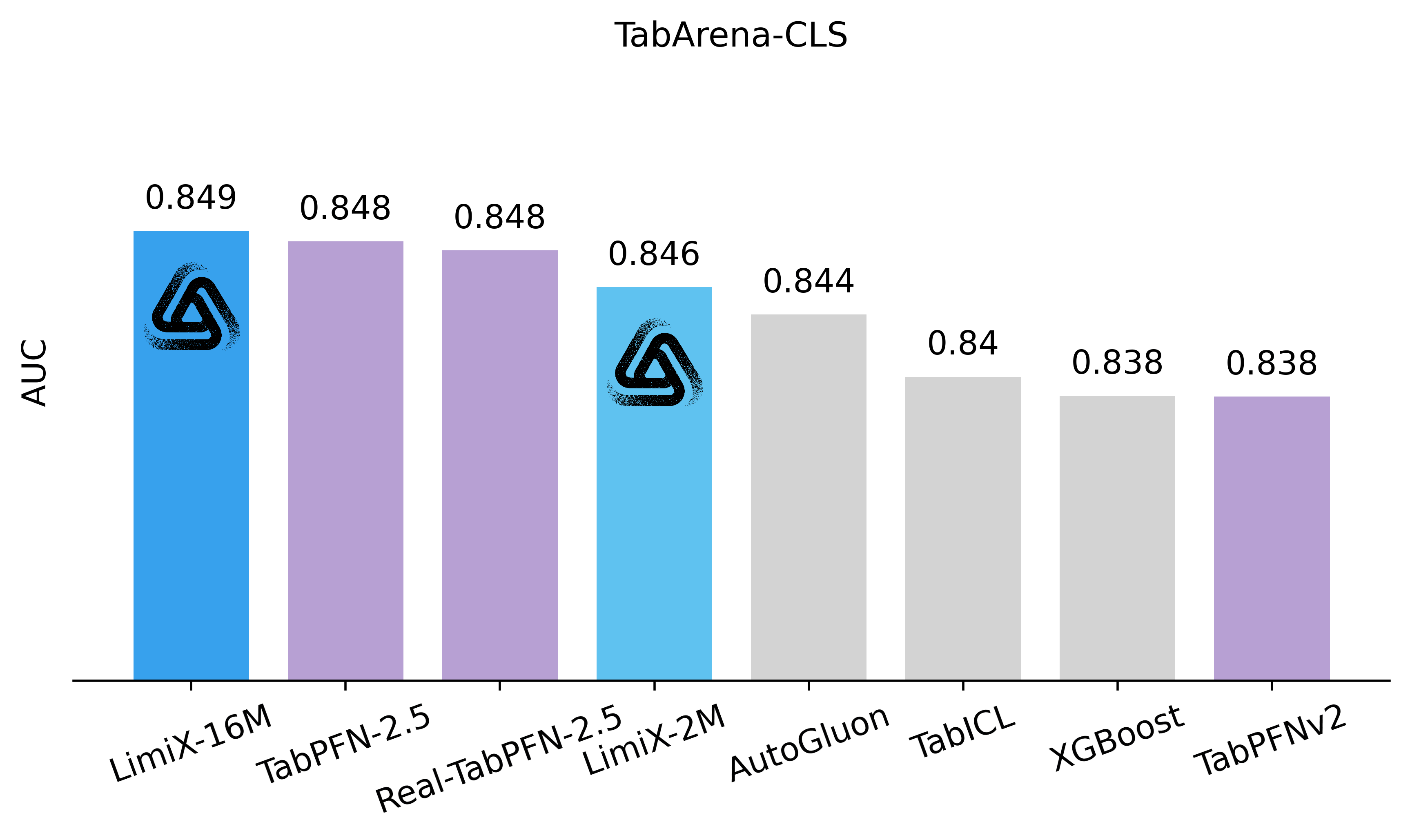
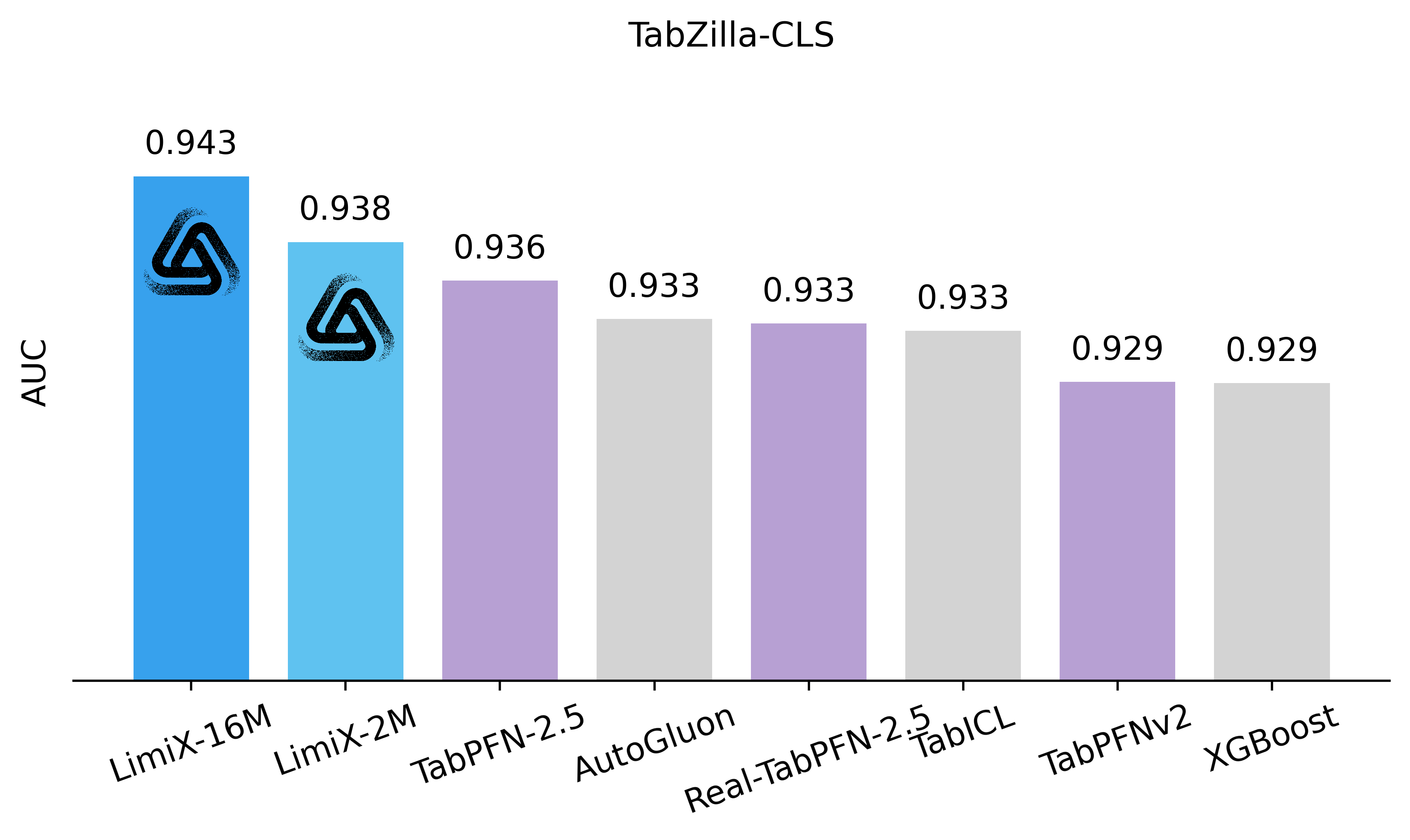
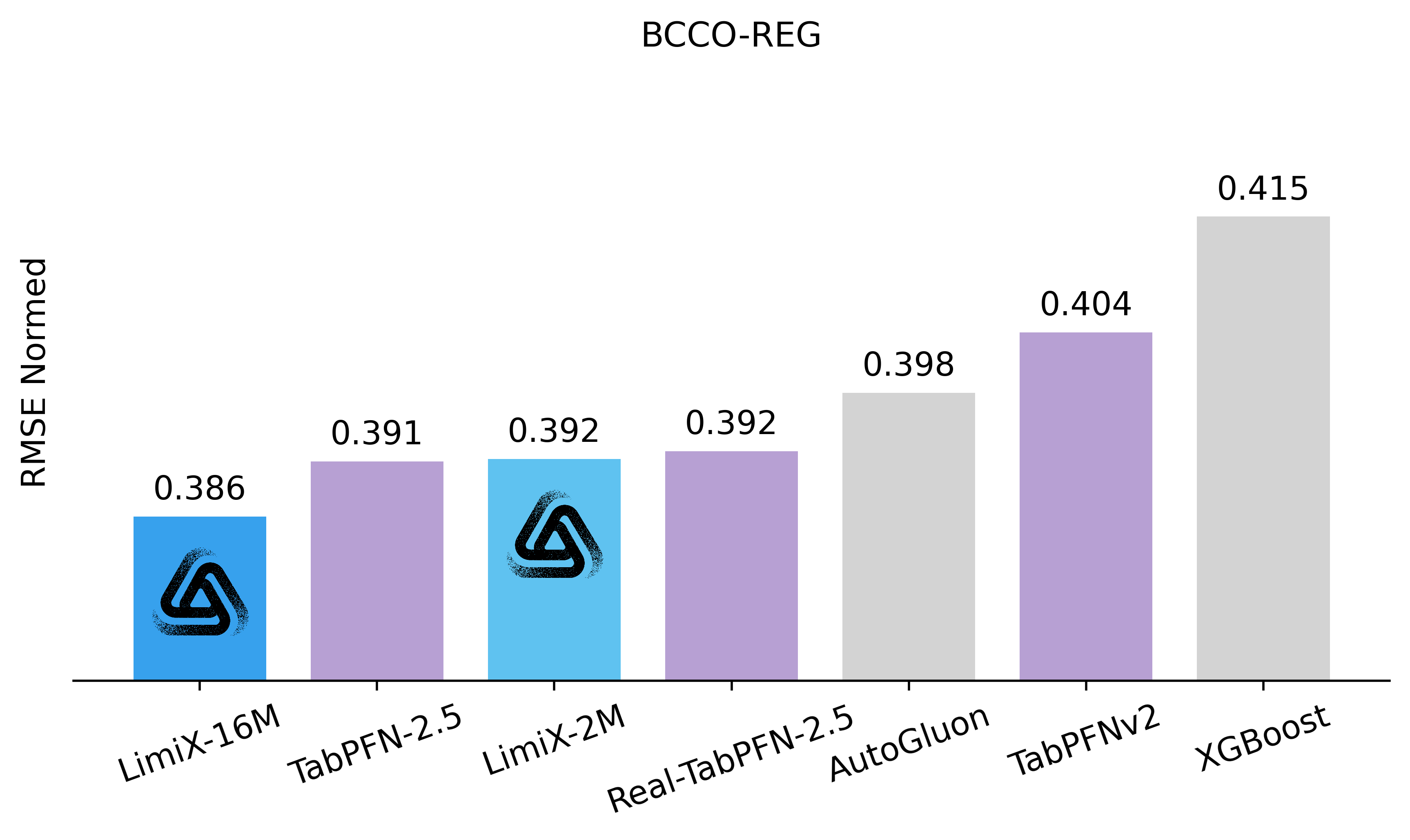
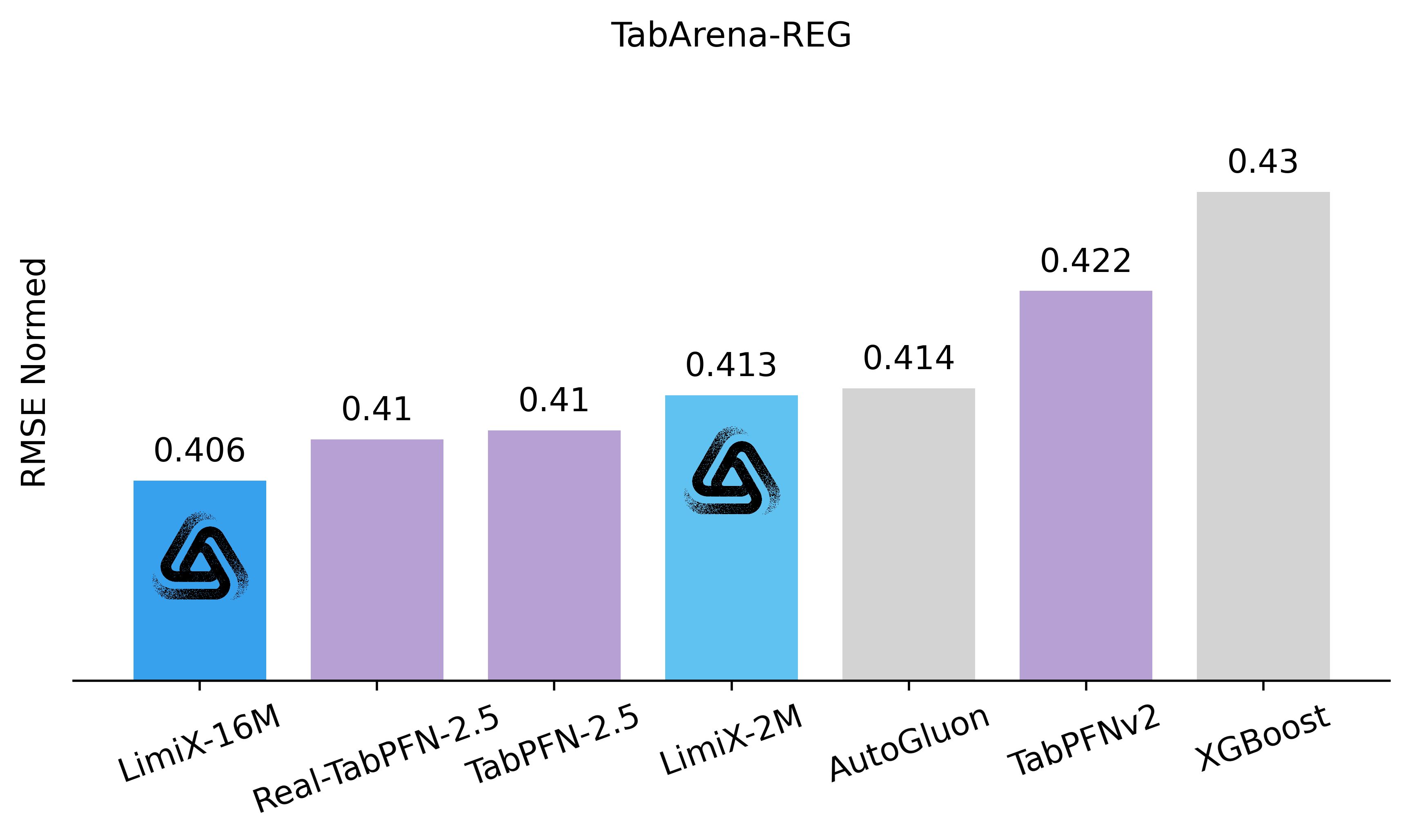
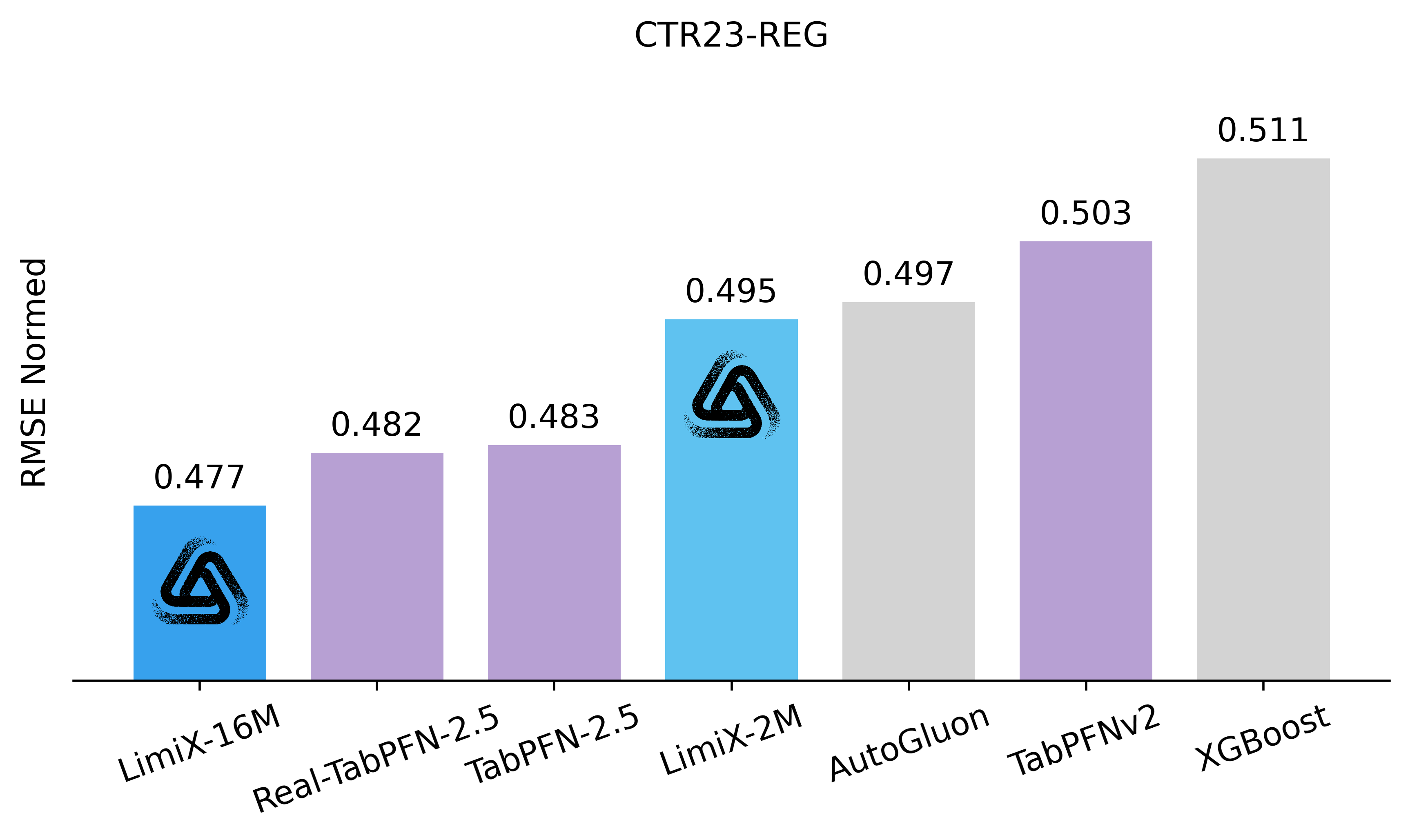
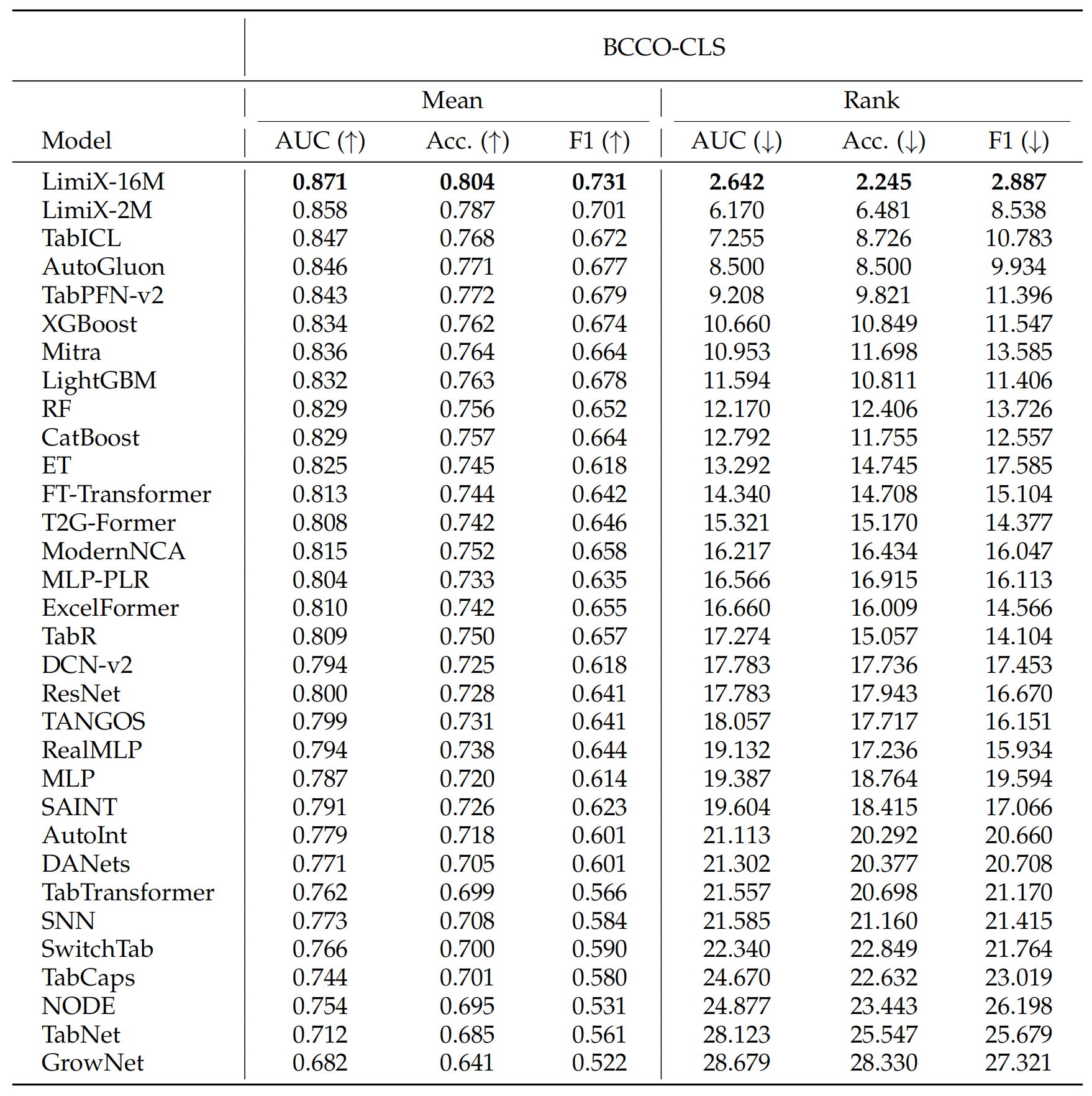
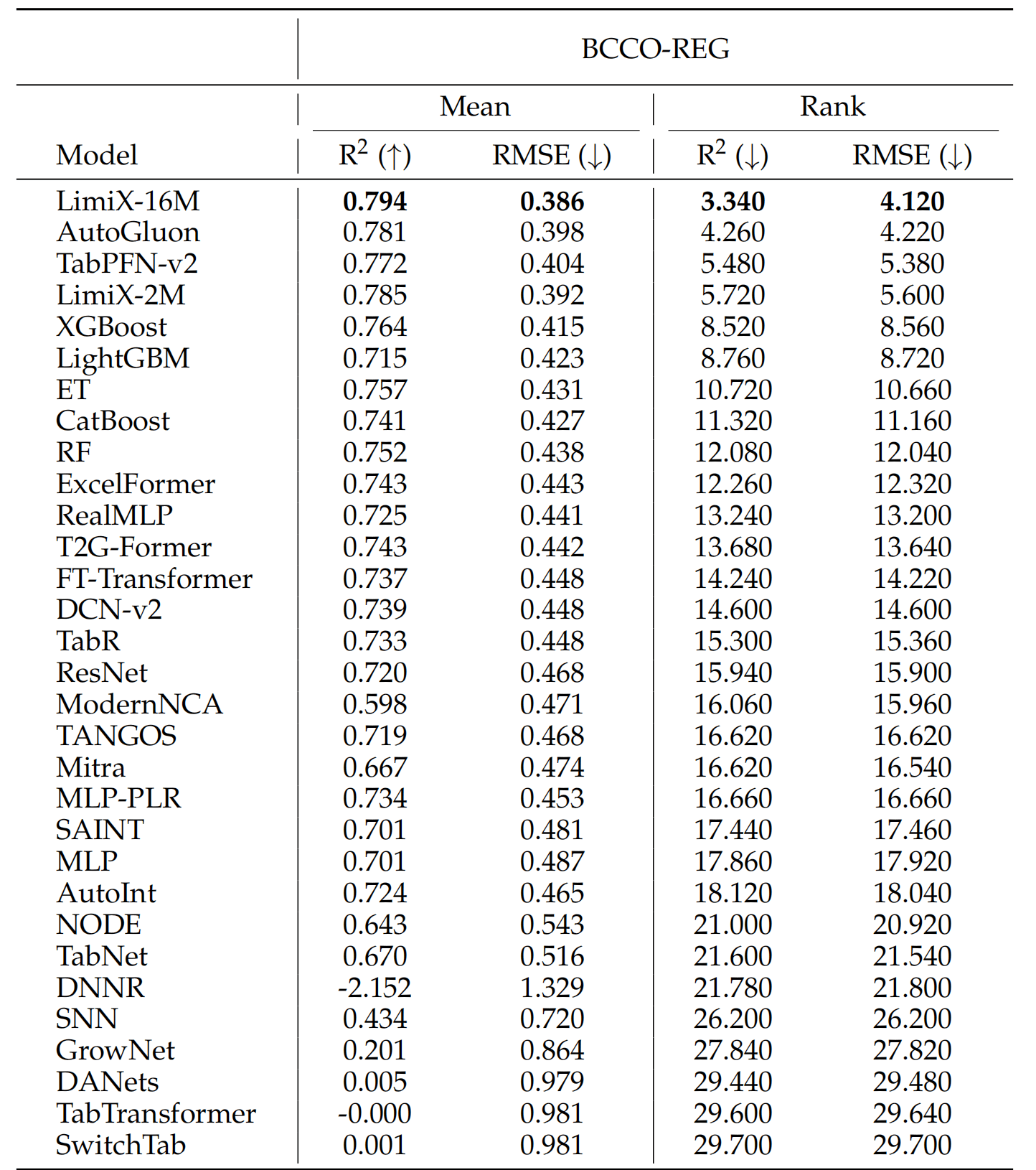
To assess the performance and generalizability of LimiX, we evaluate it across diverse tasks using multiple open-source benchmarks and compare it against state-of-the-art models in this domain. In the evaluation, Limix exhabits excellent modeling performance across all the tasks.
•Latest Results Compared with SOTA Models
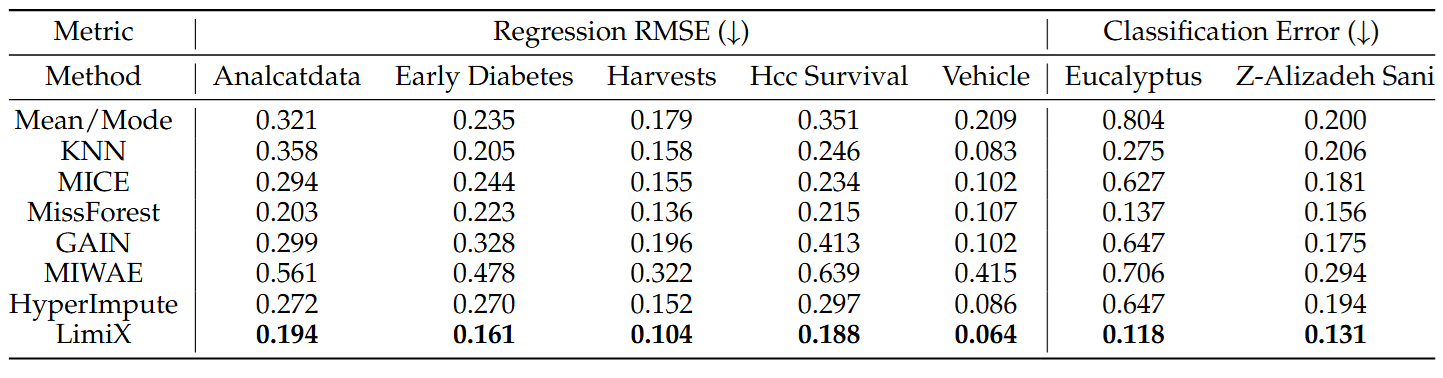
•Missing Value Imputation
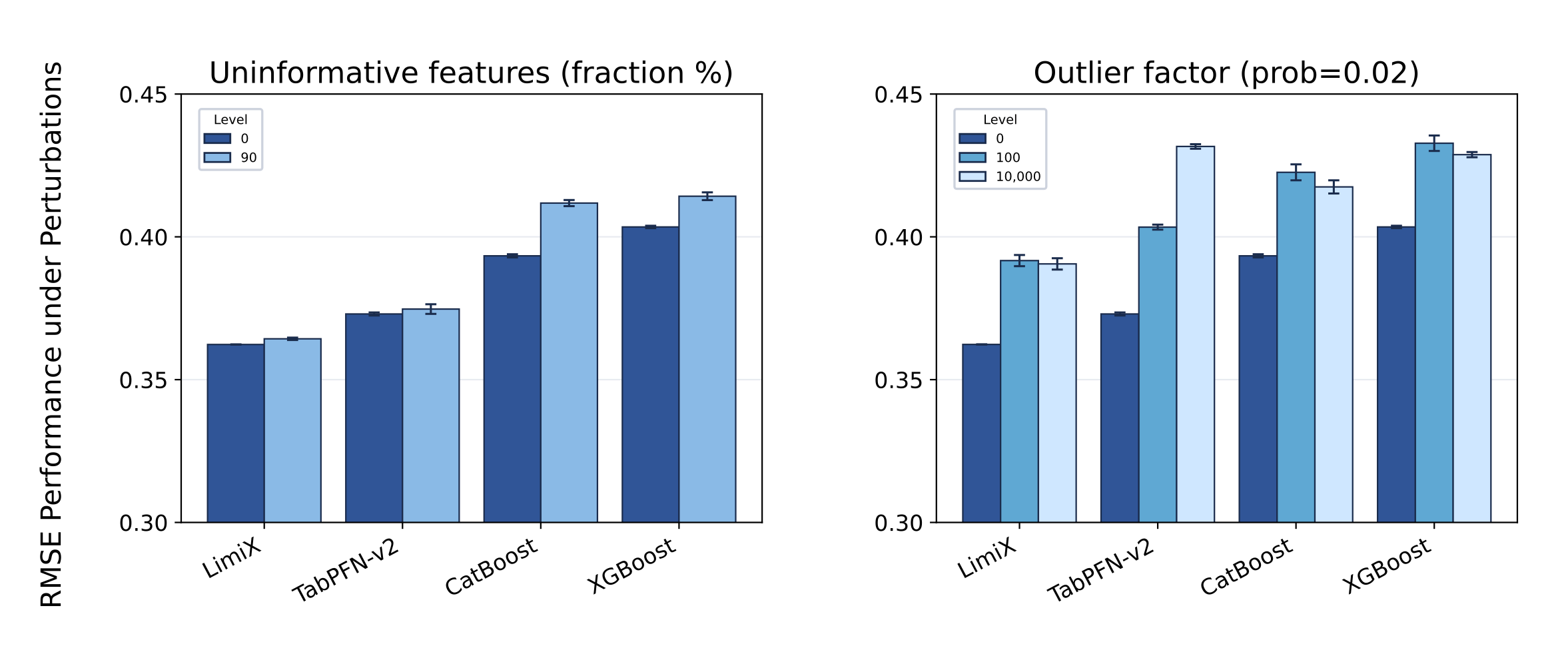
•Robustness
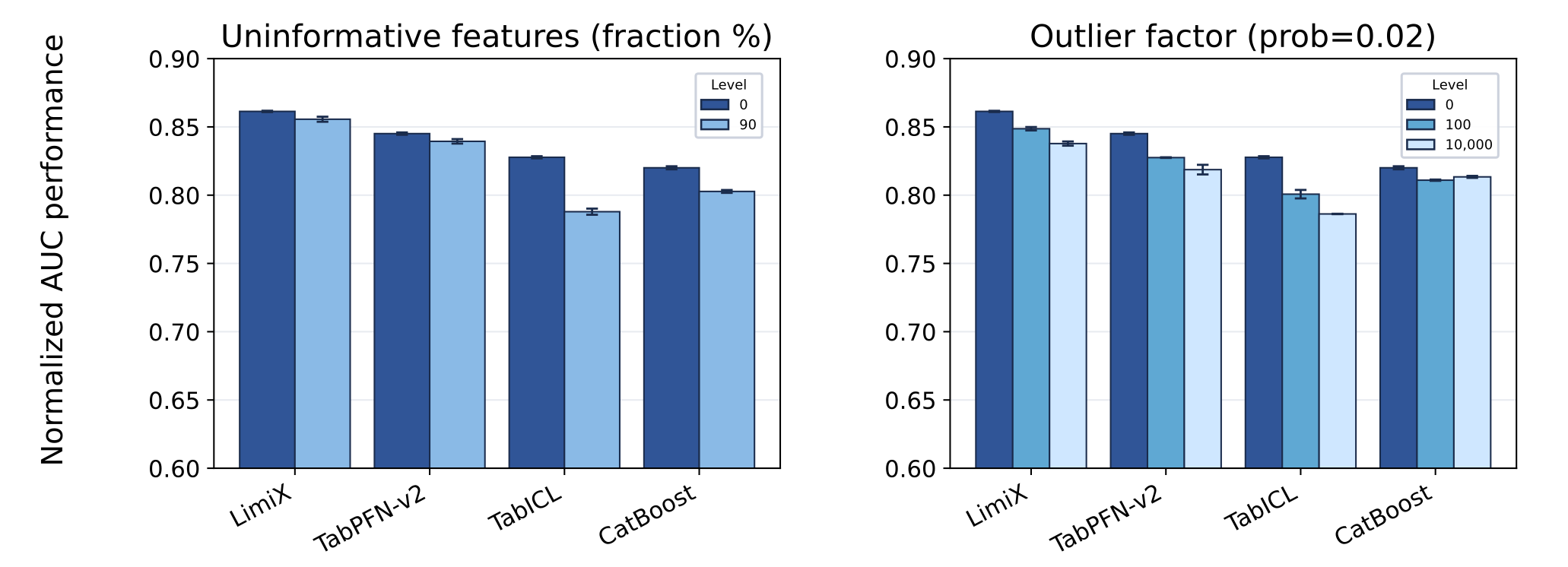
We systematically evaluated the robustness of LimiX under diverse dataset characteristics and controlled perturbations.
•Embedding
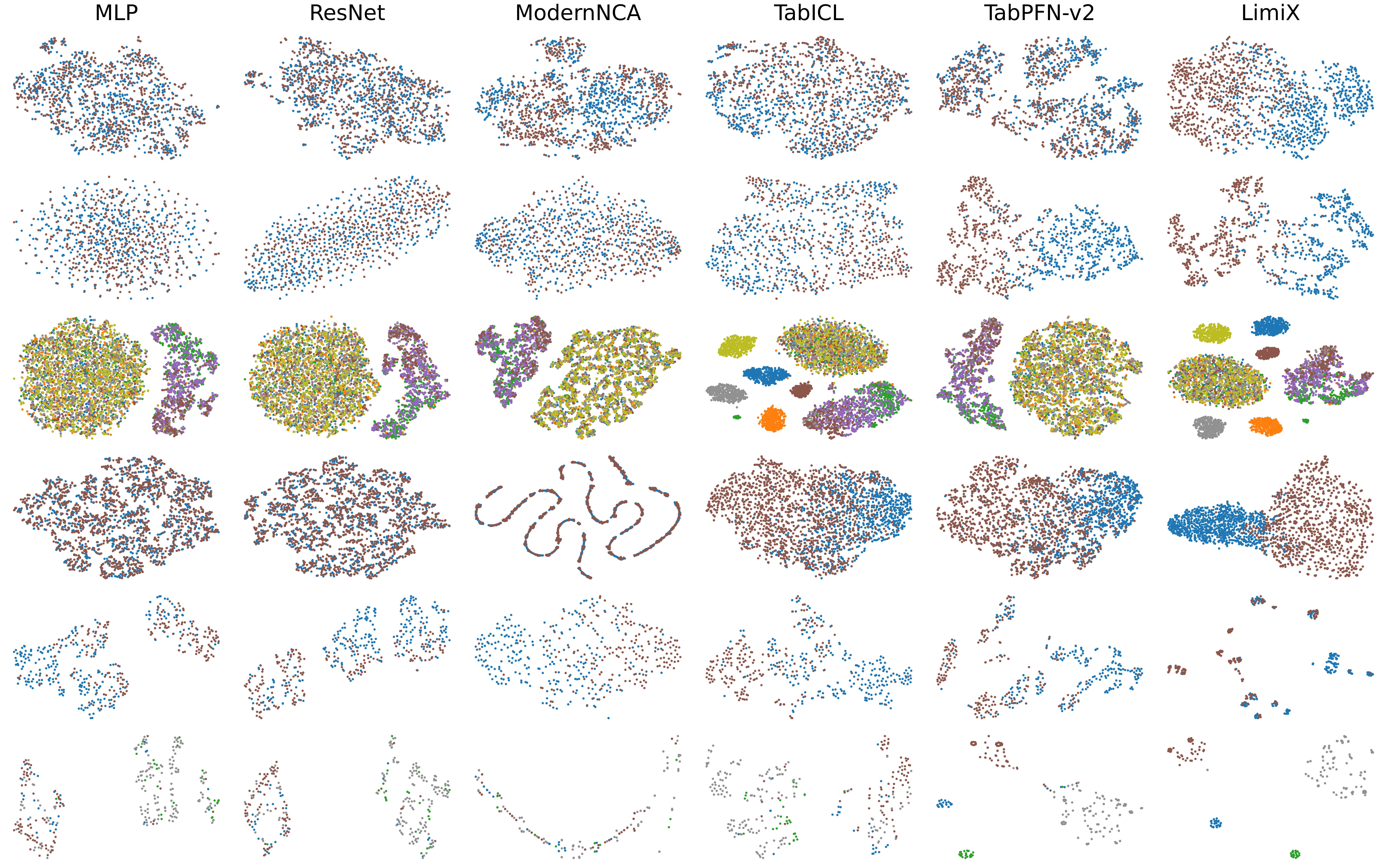
The t-SNE visualization of embeddings shows that category embeddings extracted by LimiX are more distinctly separated than those extracted by other models.
Contact Our Team
For any questions regarding this report or the LimiX model, please contact us at stableai@stable-ai.cn