

News
- 2025-11-10: LimiX-2M is officially released! Compared to LimiX-16M, this smaller variant offers significantly lower GPU memory usage and faster inference speed. The retrieval mechanism has also been enhanced, further improving model performance while reducing both inference time and memory consumption.
- 2025-08-29: LimiX V1.0 Released.
Latest Results Compared with SOTA Models
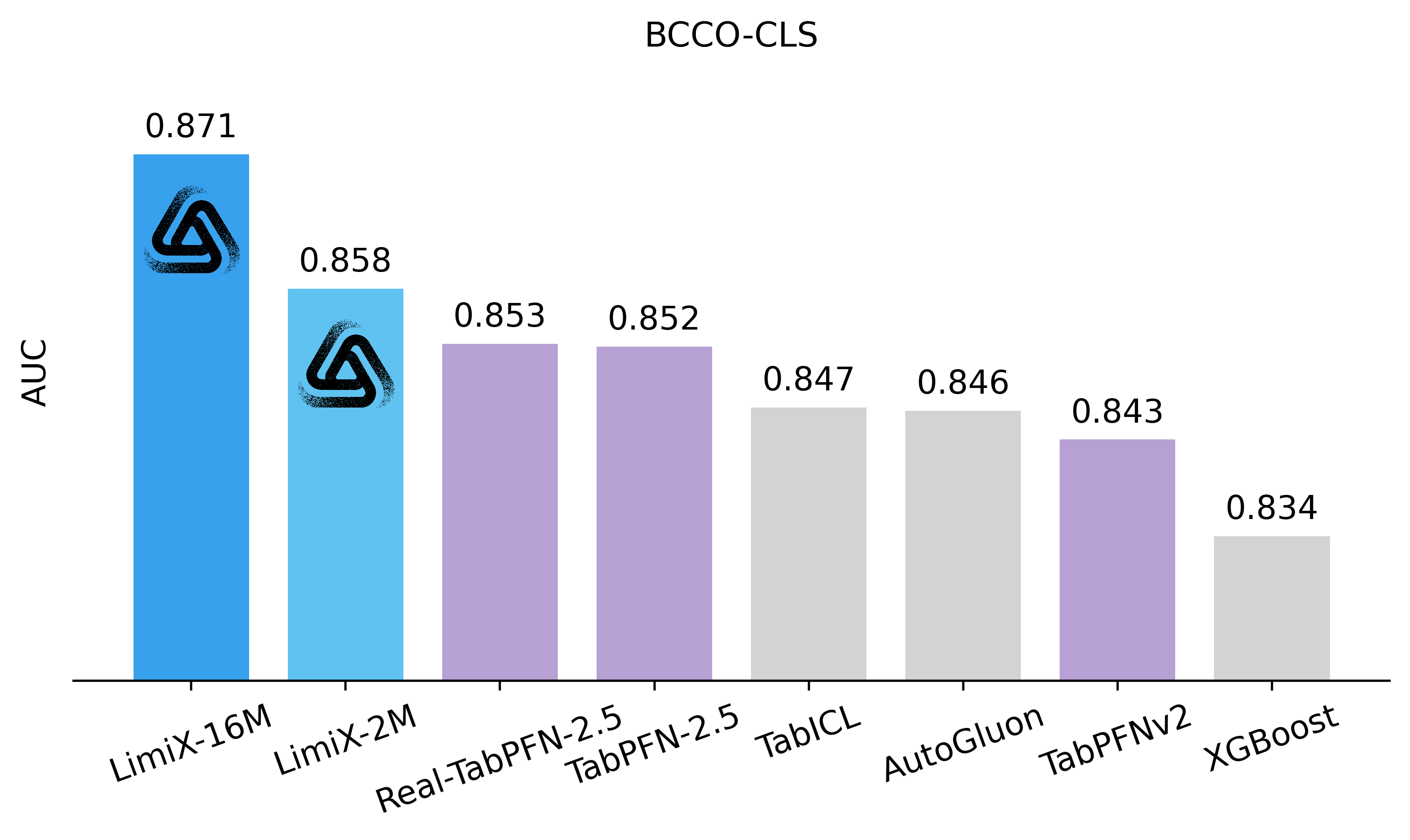
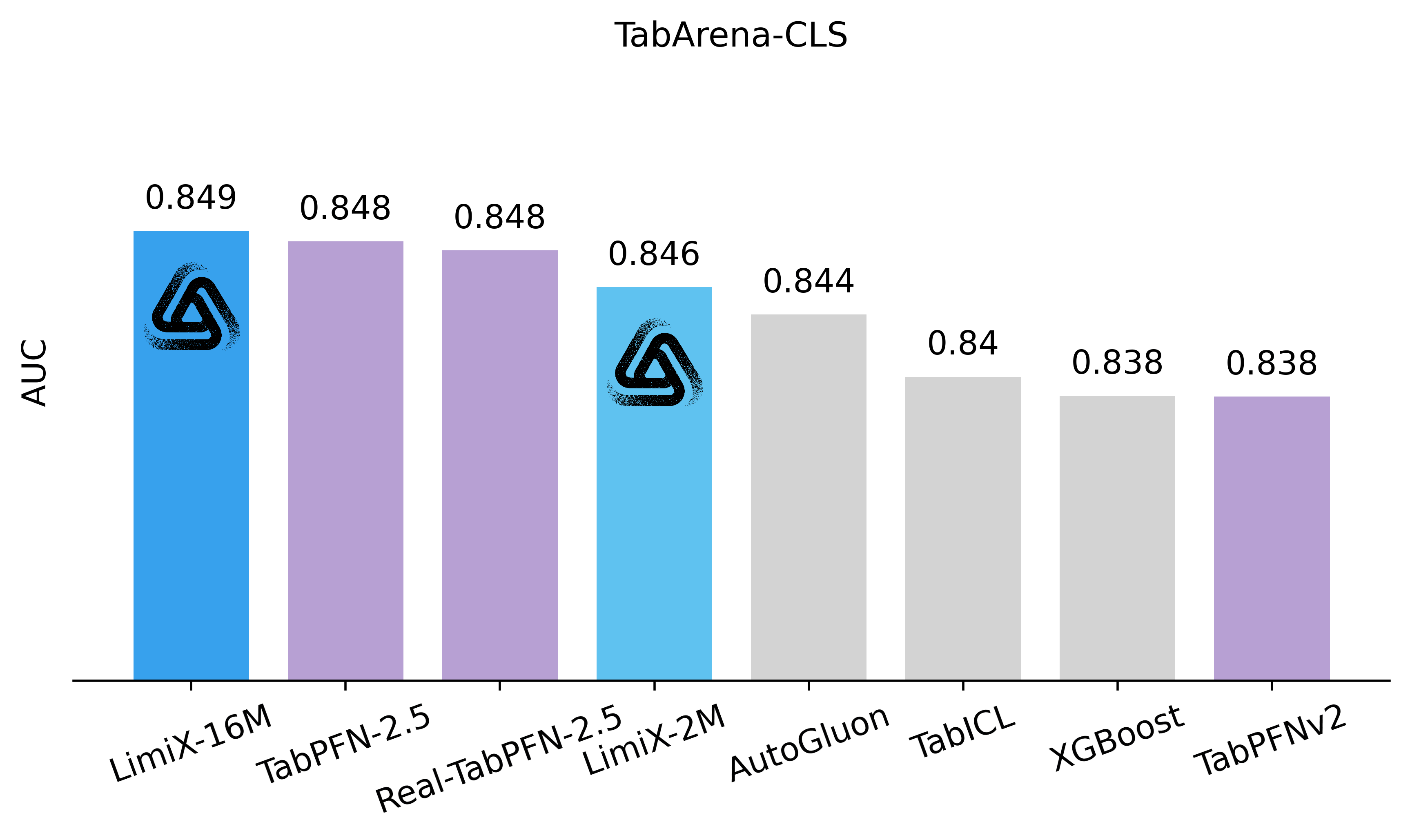
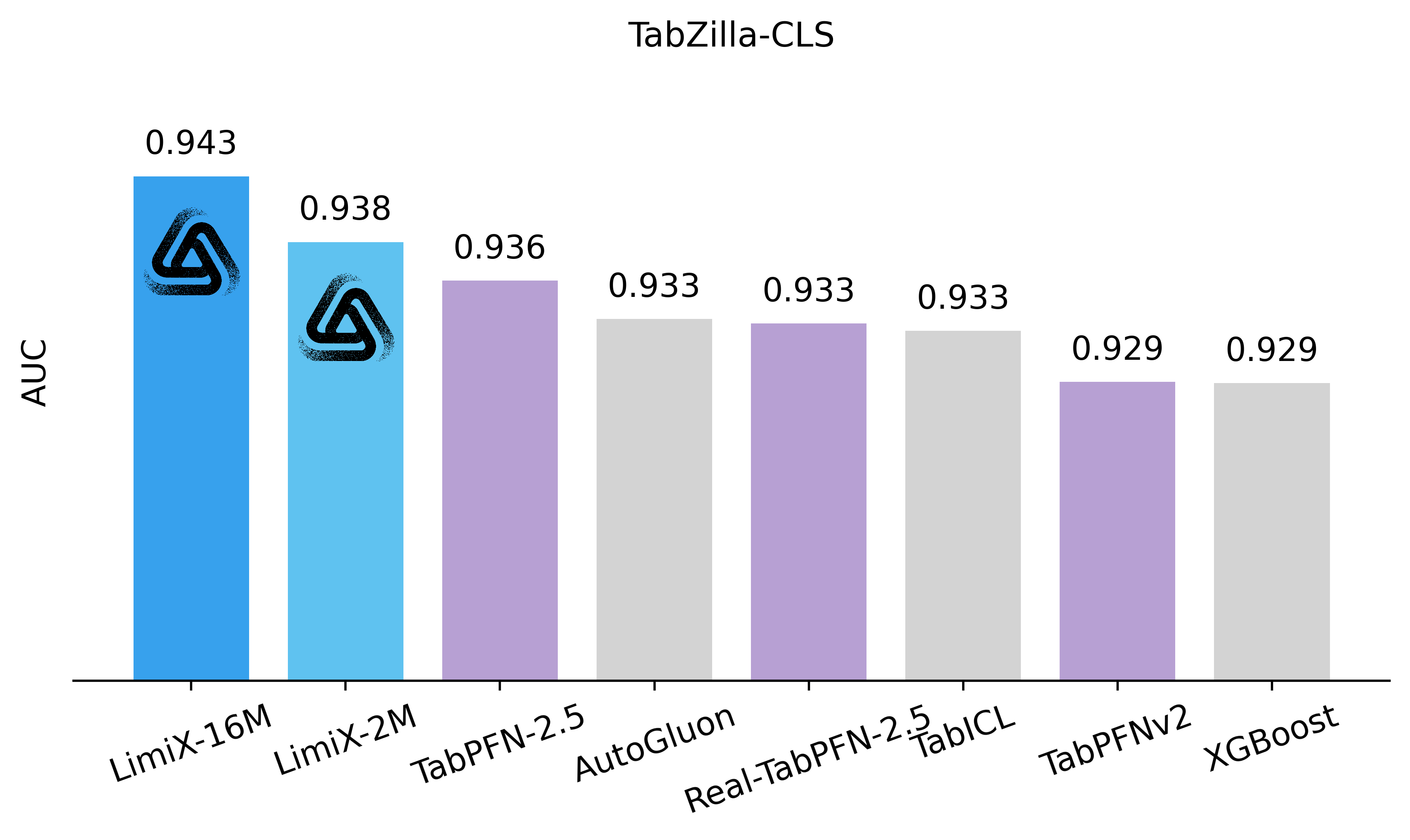
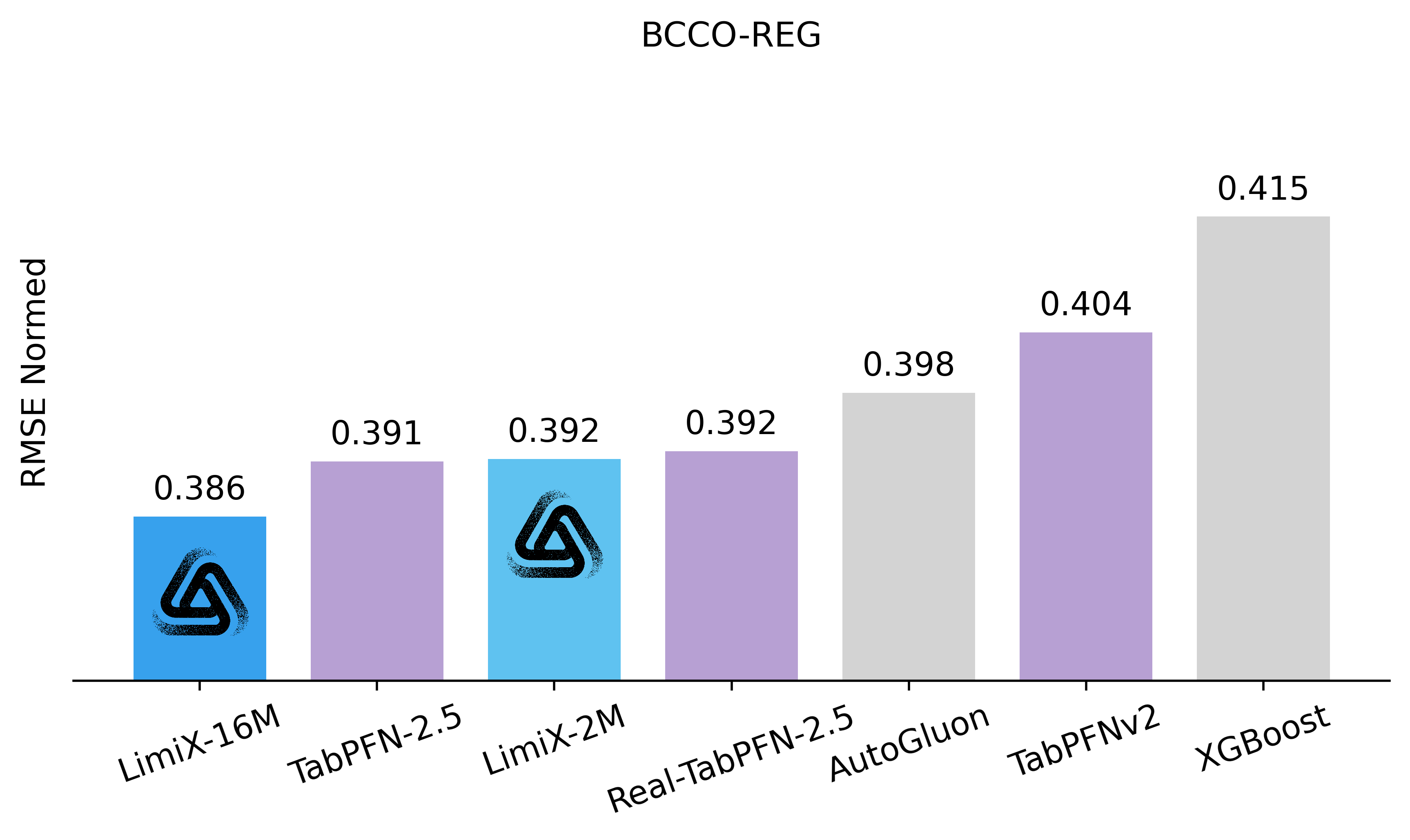
Overview
We posit that progress toward general intelligence will require different complementary classes of foundation models, each anchored to a distinct data modality and set of inductive biases. Large language models (LLMs) provide a universal interface for natural and programming languages and have rapidly advanced instruction following, tool use, and explicit reasoning over token sequences. In real-world scenarios involving structured data, LLMs still rely primarily on statistical correlations between word sequences, which limits their ability to accurately capture numerical relationships and causal rules. In contrast, large structured-data models (LDMs) are trained on heterogeneous tabular and relational data to capture conditional and joint dependencies, support diverse tasks and applications, enable robust prediction under distribution shifts, handle missingness, and facilitate counterfactual analysis and feature attribution. Here, we introduce LimiX, the first installment of our LDM series. LimiX aims to push generality further: a single model that handles classification, regression, missing-value imputation, feature selection, sample selection, and causal inference under one training and inference recipe, advancing the shift from bespoke pipelines to unified, foundation-style tabular learning.
LimiX adopts a transformer architecture optimized for structured data modeling and task generalization. The model first embeds features X and targets Y from the prior knowledge base into token representations. Within the core modules, attention mechanisms are applied across both sample and feature dimensions to identify salient patterns in key samples and features. The resulting high-dimensional representations are then passed to regression and classification heads, enabling the model to support diverse predictive tasks.
For details, please refer to the technical report at the link: LimiX_Technical_Report.pdf
Superior Performance
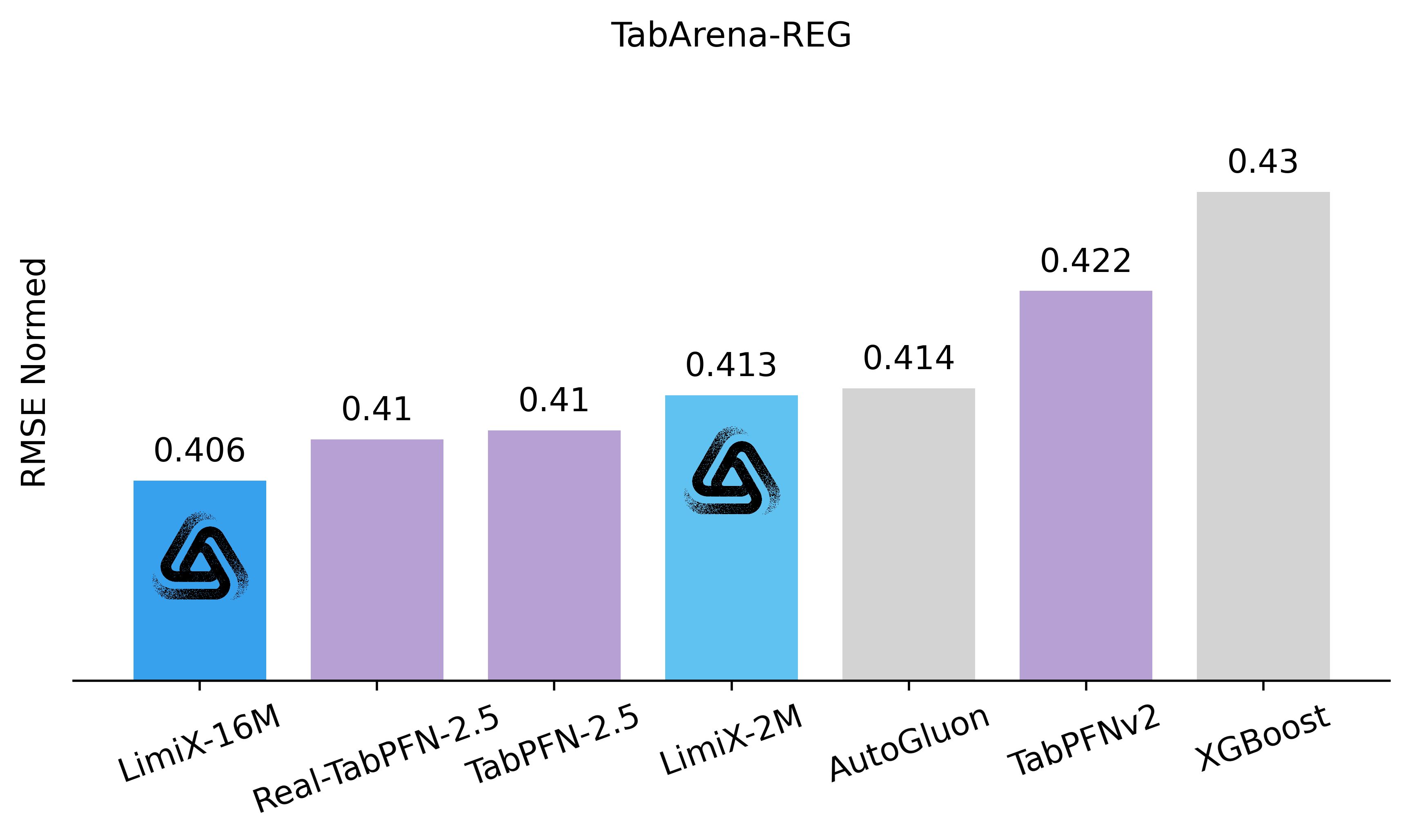
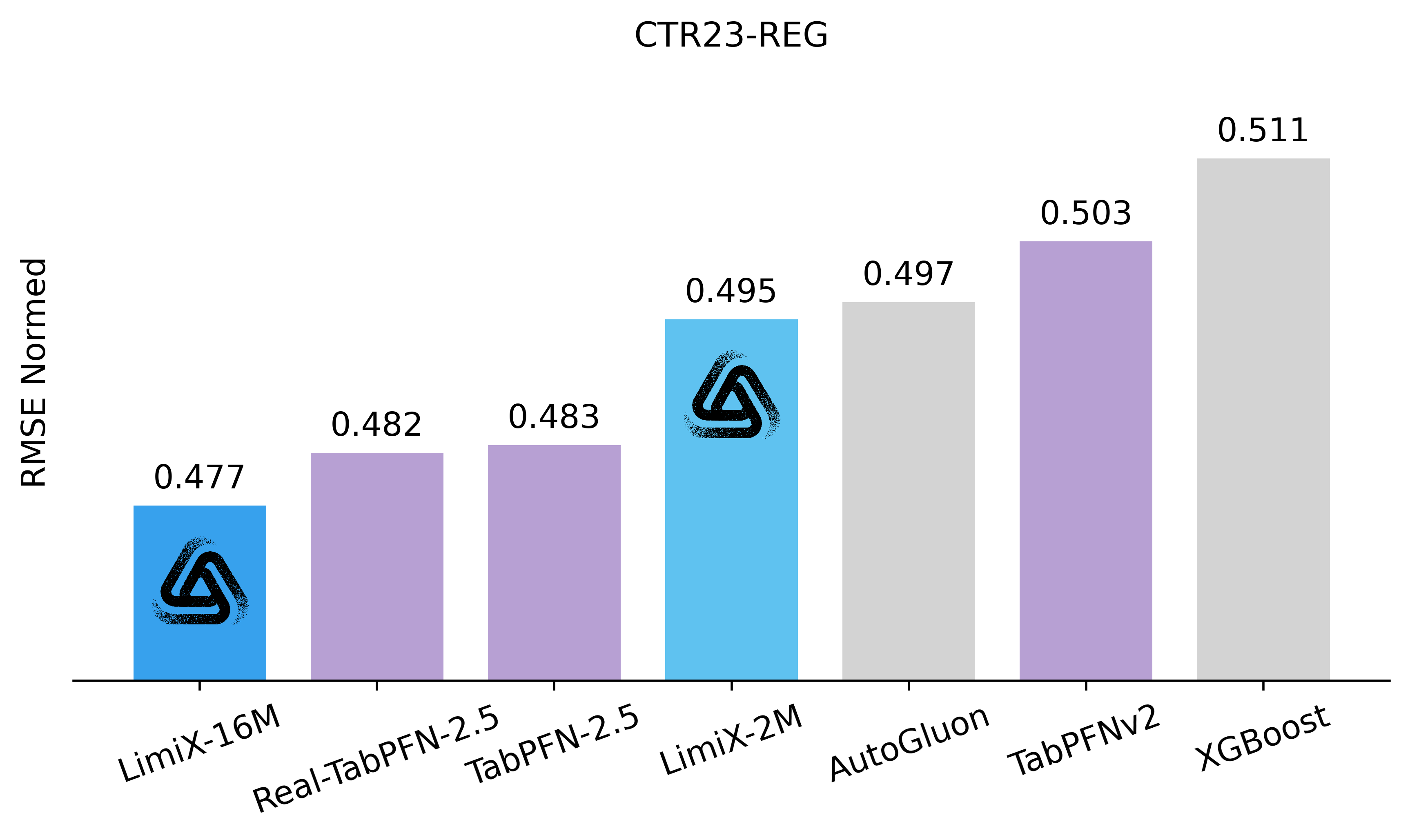
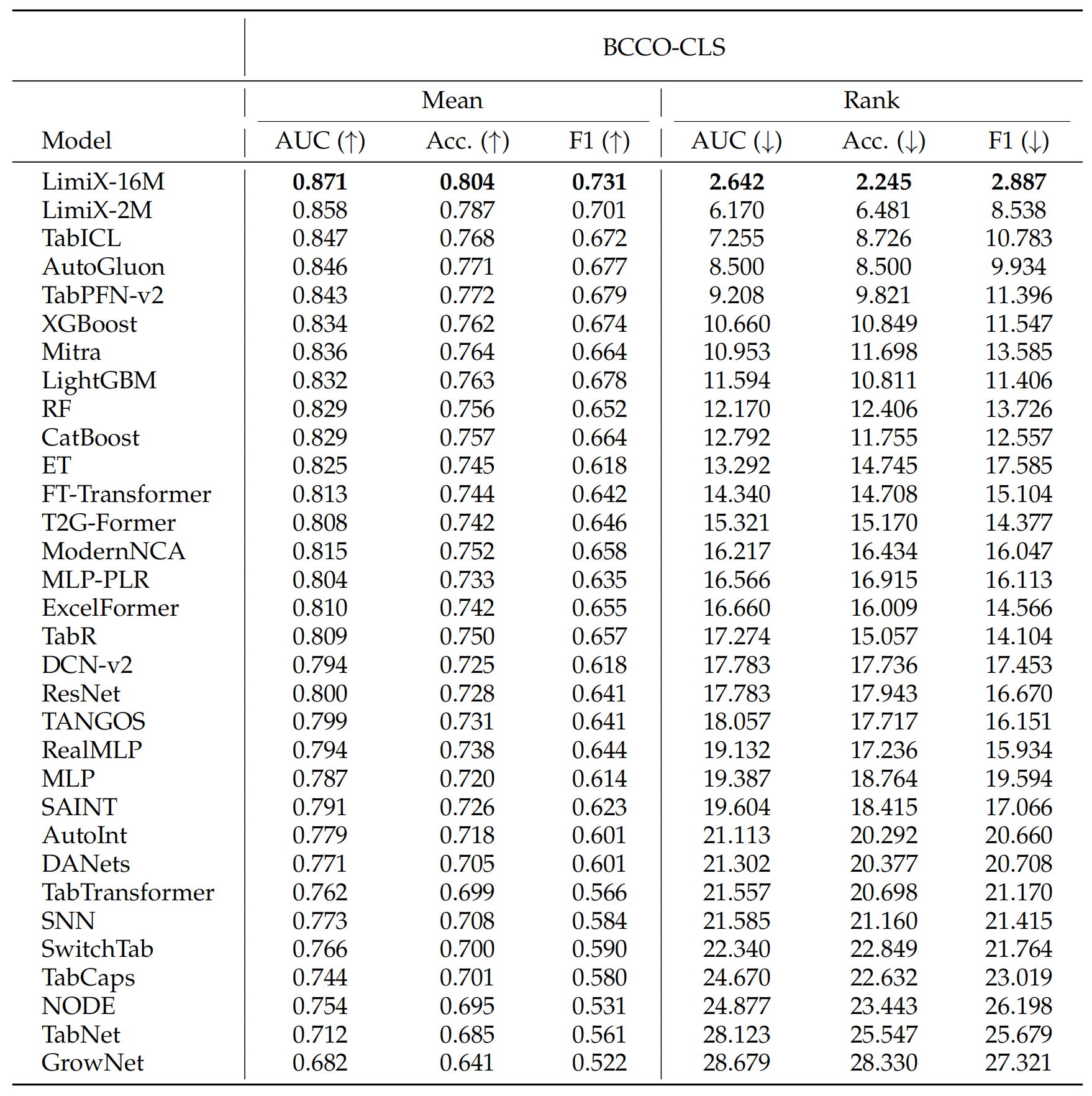
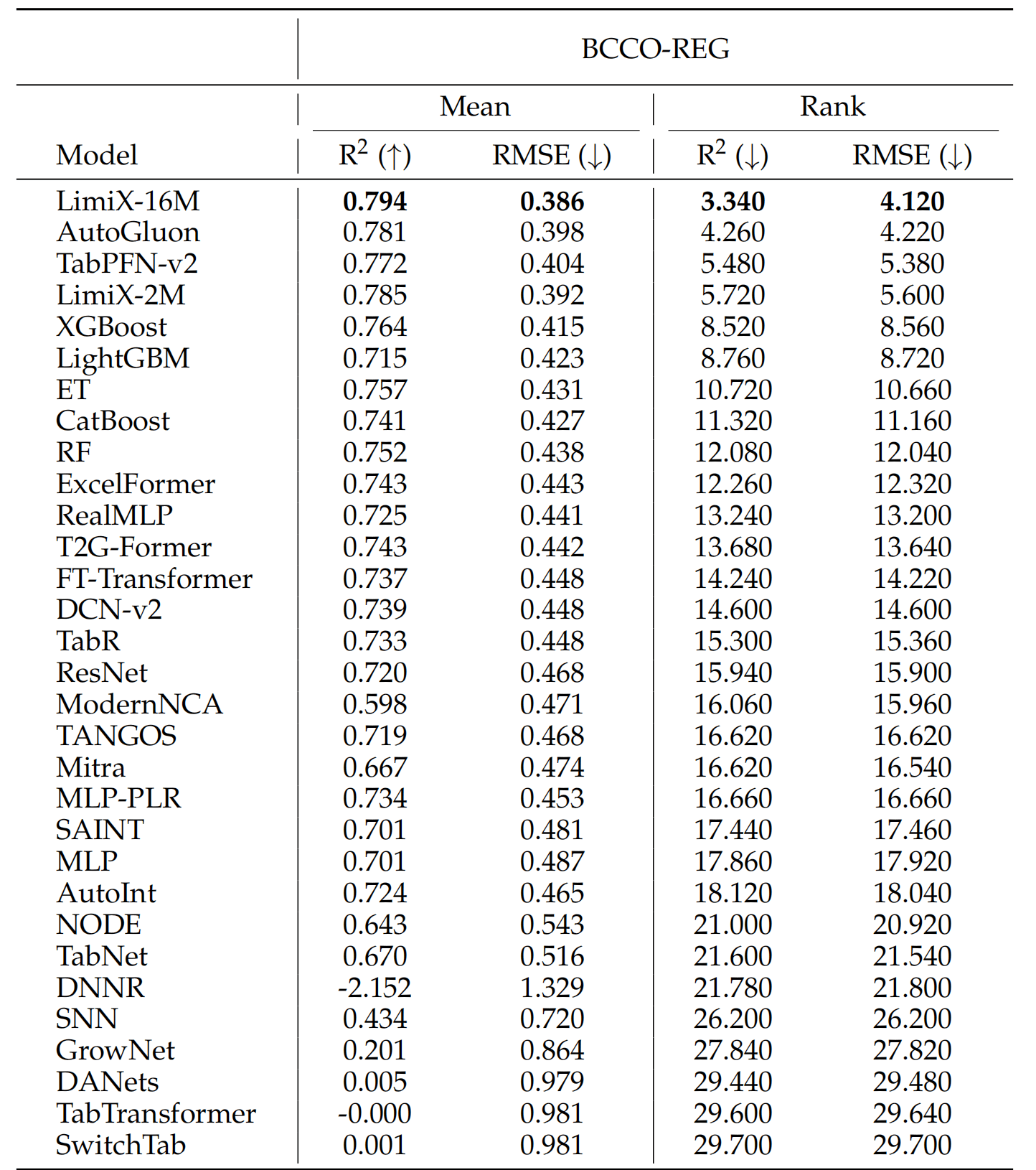
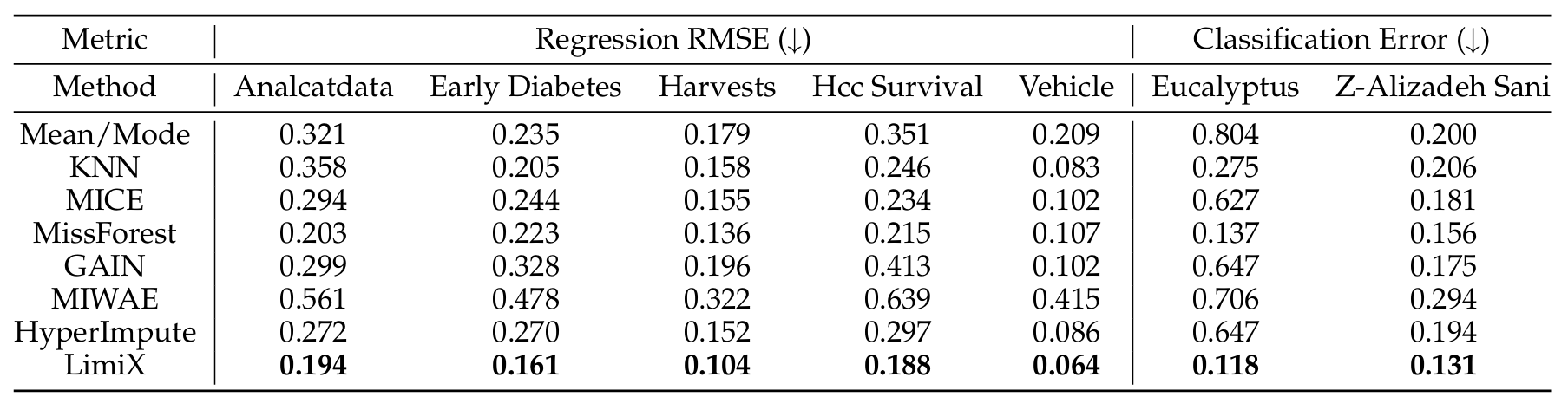
The LimiX model achieved SOTA performance across multiple tasks.
Classification
Regression
Missing Values Imputation
Tutorials
Installation
Option 1 (recommended): Use the Dockerfile
Download Dockerfile
docker build --network=host -t limix/infe:v1 --build-arg FROM_IMAGES=nvidia/cuda:12.2.0-base-ubuntu22.04 -f Dockerfile .
Option 2: Build manually
Download the prebuilt flash_attn files
wget -O flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.0.post2/flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
Install Python dependencies
pip install python==3.12.7 torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1
pip install flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
pip install scikit-learn einops huggingface-hub matplotlib networkx numpy pandas scipy tqdm typing_extensions xgboost kditransform hyperopt
Download source code
git clone https://github.com/limix-ldm/LimiX.git
cd LimiX
Inference
LimiX supports tasks such as classification, regression, and missing value imputation
Model download
| Model size | Download link | Tasks supported |
|---|---|---|
| LimiX-16M | LimiX-16M.ckpt | ✅ classification ✅regression ✅missing value imputation |
| LimiX-2M | LimiX-2M.ckpt | ✅ classification ✅regression ✅missing value imputation |
Interface description
Model Creation
class LimiXPredictor:
def __init__(self,
device:torch.device,
model_path:str,
mix_precision:bool=True,
inference_config: list|str,
categorical_features_indices:List[int]|None=None,
outlier_remove_std: float=12,
softmax_temperature:float=0.9,
task_type: Literal['Classification', 'Regression']='Classification',
mask_prediction:bool=False,
inference_with_DDP: bool = False,
seed:int=0)
| Parameter | Data Type | Description |
|---|---|---|
| device | torch.device | The hardware that loads the model |
| model_path | str | The path to the model that needs to be loaded |
| mix_precision | bool | Whether to enable the mixed precision inference |
| inference_config | list/str | Configuration file used for inference |
| categorical_features_indices | list | The indices of categorical columns in the tabular data |
| outlier_remove_std | float | The threshold is employed to remove outliers, defined as values that are multiples of the standard deviation |
| softmax_temperature | float | The temperature used to control the behavior of softmax operator |
| task_type | str | The task type which can be either "Classification" or "Regression" |
| mask_prediction | bool | Whether to enable missing value imputation |
| inference_with_DDP | bool | Whether to enable DDP during inference |
| seed | int | The seed to control random states |
Predict
def predict(self, x_train:np.ndarray, y_train:np.ndarray, x_test:np.ndarray) -> np.ndarray:
| Parameter | Data Type | Description |
|---|---|---|
| x_train | np.ndarray | The input features of the training set |
| y_train | np.ndarray | The target variable of the training set |
| x_test | np.ndarray | The input features of the test set |
Ensemble Inference Based on Sample Retrieval
For a detailed technical introduction to Ensemble Inference Based on Sample Retrieval, please refer to the technical report.
Considering inference speed, ensemble inference based on sample retrieval currently only supports hardware with specifications higher than the NVIDIA RTX 4090 GPU.
Classification Task
python inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
Regression Task
python inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
Customizing Data Preprocessing for Inference Tasks
First, Generate the Inference Configuration File
generate_inference_config()
Classification Task
Single GPU or CPU
python inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
Multi-GPU Distributed Inference
torchrun --nproc_per_node=8 inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data --inference_with_DDP
Regression Task
Single GPU or CPU
python inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
Multi-GPU Distributed Inference
torchrun --nproc_per_node=8 inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data --inference_with_DDP
Retrieval Optimization Project
This project implements an optimized retrieval system. To achieve the best performance, we utilize Optuna for hyperparameter tuning of retrieval parameters.
Installation
Ensure you have the required dependencies installed:
pip install optuna
Usage
For standard inference using pre-optimized parameters, refer to the code below:
searchInference = RetrievalSearchHyperparameters(
dict(device_id=0,model_path=model_path), X_train, y_train, X_test, y_test,
)
config, result = searchInference.search(n_trials=10, metric="AUC",
inference_config='config/cls_default_retrieval.json',task_type="cls")
This will launch an Optuna study to find the best combination of retrieval parameters for your specific dataset and use case.
Classification
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.model_selection import train_test_split
from huggingface_hub import hf_hub_download
import numpy as np
import os, sys
ROOT_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
if ROOT_DIR not in sys.path:
sys.path.insert(0, ROOT_DIR)
from inference.predictor import LimiXPredictor
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
model_file = hf_hub_download(repo_id="stableai-org/LimiX-16M", filename="LimiX-16M.ckpt", local_dir=".")
clf = LimiXPredictor(device=torch.device('cuda'), model_path='your model path', inference_config='config/cls_default_noretrieval.json')
prediction = clf.predict(X_train, y_train, X_test)
print("roc_auc_score:", roc_auc_score(y_test, prediction[:, 1]))
print("accuracy_score:", accuracy_score(y_test, np.argmax(prediction, axis=1)))
For additional examples, refer to inference_classifier.py
Regression
from functools import partial
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from huggingface_hub import hf_hub_download
try:
from sklearn.metrics import root_mean_squared_error as mean_squared_error
except:
from sklearn.metrics import mean_squared_error
mean_squared_error = partial(mean_squared_error, squared=False)
import os, sys
ROOT_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
if ROOT_DIR not in sys.path:
sys.path.insert(0, ROOT_DIR)
from inference.predictor import LimiXPredictor
house_data = fetch_california_housing()
X, y = house_data.data, house_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
y_mean = y_train.mean()
y_std = y_train.std()
y_train_normalized = (y_train - y_mean) / y_std
y_test_normalized = (y_test - y_mean) / y_std
data_device = f'cuda:0'
model_path = hf_hub_download(repo_id="stableai-org/LimiX-16M", filename="LimiX-16M.ckpt", local_dir=".")
model = LimiXPredictor(device=torch.device('cuda'), model_path=model_path, inference_config='config/reg_default_noretrieval.json')
y_pred = model.predict(X_train, y_train_normalized, X_test)
# Compute RMSE and R²
y_pred = y_pred.to('cpu').numpy()
rmse = mean_squared_error(y_test_normalized, y_pred)
r2 = r2_score(y_test_normalized, y_pred)
print(f'RMSE: {rmse}')
print(f'R2: {r2}')
For additional examples, refer to inference_regression.py
Missing value imputation
For the demo file, please check examples/demo_missing_value_imputation.py
Link
- LimiX Technical Report: LimiX_Technical_Report.pdf
- Balance Comprehensive Challenging Omni-domain Classification Benchmark: bcco_cls
- Balance Comprehensive Challenging Omni-domain Regression Benchmark: bcco_reg
License
The code in this repository is open-sourced under the Apache-2.0 license, while the usage of the LimiX model weights is subject to the Model License. The LimiX weights are fully available for academic research and may be used commercially upon obtaining proper authorization.
Usage tips
When to use LimiX
LimiX is designed for tabular datasets comprising fewer than 50,000 samples and fewer than 10,000 features. Larger datasets increase the model’s hardware requirements, while the performance gains compared to models such as XGBoost may be limited.
Intended use cases for LimiX
LimiX can be applied to both classification、 regression and missing value imputation tasks involving tabular data. Compared with methods such as XGBoost and CatBoost, it demonstrates faster training and inference speeds, while achieving superior model performance.
Limitations in the use of LimiX
When the dataset comprises a large number of samples, LimiX may require more hardware resources and exhibit lower performance compared to supervised models such as XGBoost.
Computational and time requirements
Leveraging its model architecture, LimiX attains higher processing speeds than conventional machine learning methods and does not necessitate the extensive GPU resources typically required by large language models.
Contact Our Team
For any questions regarding this report or the LimiX model, please contact us at stableai@stable-ai.cn